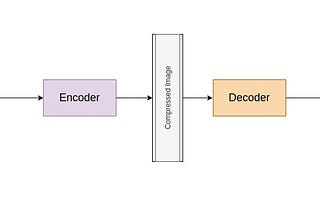
PinnedGarima NishadClassification Model On Custom Dataset Using Tensorflow.jsBuild a model from scratch and use that to get a prediction on the browser.3 min read·Jun 1, 2021--1--1
PinnedGarima NishadReconstruct corrupted data using Denoising Autoencoder(Python code)This article will help you demystify denoising using autoencoder in few minutes!!6 min read·Aug 3, 2020----
PinnedGarima NishadYou Only Look Once(YOLO): Implementing YOLO in less than 30 lines of Python CodeYou Only Look Once is a real-time object detection algorithm, that avoids spending too much time on generating region proposals.Instead of…5 min read·Mar 1, 2019--9--9
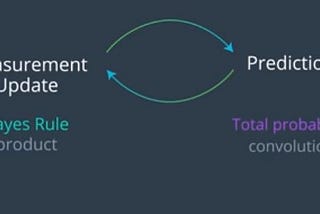
PinnedGarima NishadKalman Filters : A step by step implementation guide in pythonThis article will simplify the Kalman Filter for you. Hopefully you’ll learn and demystify all these cryptic things that you find in…6 min read·Mar 8, 2019--7--7
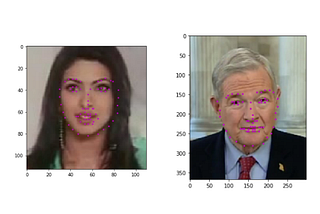
PinnedGarima NishadFacial Keypoint Detection: Detect relevant features of face in a go using CNN & your own dataset…Facial key-points are relevant for a variety of tasks, such as face filters, emotion recognition, pose recognition, and so on. So if…4 min read·Mar 23, 2019--1--1
Garima NishadinGood AudienceThe Ethics of Machine Learning: Bias and Fairness in Algorithmic Decision MakingLooking at bias and variance from another perspective..5 min read·Apr 6, 2023----
Garima NishadinGood AudienceLaTeX made easy: Learn the shortcuts and tricks to create beautiful documents with minimal effort.Learn the secret LaTeX hacks to elevate your work to the next level!4 min read·Jan 27, 2023----
Garima NishadThe Key to Better Code: Best Practices and TipsDiscover the Secret to Writing Code That Impresses Everyone.5 min read·Jan 5, 2023----
Garima Nishad“From Novice to Pro: A Comprehensive Guide to Image Classification with Keras”You won’t believe the accuracy of this image classification model built with Keras..6 min read·Jan 5, 2023----
Garima Nishad21 Data Science Hacks: A Cheat Sheet for Data Science BeginnersFew commands/codes that I use as a Data Scientist almost every day3 min read·Jul 29, 2022----